PDF version of this post is here The importance of objective quality metric methods cannot be underestimated: such methods are being used in automated images restoration algorithms, for comparison of images compression algorithms and so on. Quality metrics are graphically presented in Fig.
1.
All proposed quality metrics can divided to two general classes1: subjective and objective [2].
Subjective evaluation of images quality is oriented on Human Vision System (HVS). As it was mentioned in [3], the best way to assess the quality of an image is perhaps to look at it because human eyes are the ultimate receivers in most image processing environments. The subjective quality measurement Mean Opinion Score (MOS) has been used for many years.
Objective metrics include Mean Squared Error (MSE), or $L_p$-norm [4,5], and measures that are mimicking the HVS such as [6,7,8,9,10,11]. In particular, it is well known that a large number of neurons in the primary visual cortex are tuned to visual stimuli with specific spatial locations, frequencies, and orientations. Images quality metrics that incorporate perceptual quality measures by considering human visual system (HVS) were proposed in [12,13,14,15,16]. Image quality measure (IQM) that computes image quality based on the 2-D spatial frequency power spectrum of an image was proposed in [10]. But still such metrics have poor performance in real applications and widely criticized for not correlating well with perceived quality measurement [3].
As a promising techniques for images quality measure, Universal Quality Index [17,3], Structural SIMilarity index [18,19], and Multidimensional Quality Measure Using SVD [1] are worth to be mentioned 2.
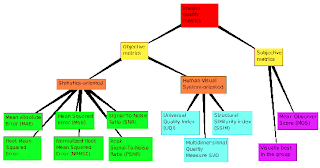
Figure 1: Types of images quality metrics.
So there are three objective methods of images' quality estimation to be discussed below: the UQI, the SSIM, and MQMuSVD. Brief information about main ideas of those metrics is given. But first of all, let me render homage to a mean squared error (MSE) metric.
Considering that
$x={x_i | i = 1,2,\dots N}$ and $y={x_i | i = 1,2,\dots N}$ are two images, where N is the number of image's pixels, the MSE between these images is:
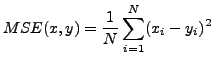
Of course, there is more general and well-suitable formulation of MSE for images processing given by Fienup [
5]:
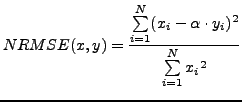 | (2) |
where
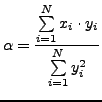 | (3) |
Such NRMSE metrics allows to estimate quality of images especially in various applications of digital deconvolution techniques. Although Eq.
2 is better than pure MSE, the NRMSE metric have been criticizing a lot.
As it was written in remarkable paper [19], the MSE is used commonly for many reasons. The MSE is simple, parameter-free, and easy to compute. Moreover, the MSE has clear physical meaning as the energy of the error signal. Such an energy measure is preserved after any orthogonal linear transformation, such as Fourier transform. The MSE is widely used in optimization tasks and in deconvolution problem [21,22,23]. Finally, competing algorithms have most often been compared using the MSE or Peak SNR ratio.
But problems arising when one is trying to predict human perception of image fidelity and quality using MSE. As it was shown in [19], the MSE is very similar despite the differences in image's distortions. That is why there were many attempts to overcome MSE's limitations and find a new images quality metrics. Some of them are briefly discussed below.
The new metric of images quality called ``Multidimensional Quality Measure Using SVD'' was proposed in [
1]. The main idea is that every real matrix A can be decomposed into a product of 3 matrices A = USV
T, where U and V are orthogonal matrices, U
TU = I, V
TV = I, and
$S = diag (s_1, s_2, \dots)$. The diagonal entries of S are called the singular values of A, the columns of U are called the left singular vectors of A, and the columns of V are called the right singular vectors of A. This decomposition is known as the Singular Value Decomposition (SVD) of A [
24]. If the SVD is applied to the full images, we obtain a global measure whereas if a smaller block is used, we compute the local error in that block:
 $s_i$ are the singular values of the original block, $\hat{s}_i$ are the singular values of the distorted block, and N is the block size. If the image size is $K$, we have $(K/N) \times (K/N)$ blocks. The set of distances, when displayed in a graph, represents a ``distortion map''.
$s_i$ are the singular values of the original block, $\hat{s}_i$ are the singular values of the distorted block, and N is the block size. If the image size is $K$, we have $(K/N) \times (K/N)$ blocks. The set of distances, when displayed in a graph, represents a ``distortion map''.
As a more promising new paradigm of images quality measurements, a universal image quality index was proposed in [
17]. This images quality metric is based on the following idea:
The main function of the human eyes is to extract structural information from the viewing field, and the human visual system is highly adapted for this purpose. Therefore, a measurement of structural distortion should be a good approximation of perceived image distortion.
The key point of the new philosophy is the switch from error measurement to structural distortion measurement. So the problem is how to define and quantify structural distortions. First, let's define a necessary mathematics [
17] for original image X and test image Y . The universal quality index can be written as [
3]:
 | (5) |
where
The first component is the linear correlation coefficient between x and y, i.e., this is a measure of loss of correlation. The second component measures how close the mean values are between x and y, i.e., luminance distortion. The third component measures how similar the variances of the signals are, i.e., contrast distortion.
UQI quality measurement method is applied to local regions using sliding window approach. For overall quality index to be obtained, average value of local quality indexes $Q_i$ must be calculated:
 | (6) |
As it mentioned in [17], the average quality index UQI coincides with the mean subjective ranks of observers. That gives to researchers a very powerful tool for images' quality estimation.
The Structural Similarity index (SSIM) that is proposed in [
18] is a generalized form of a Universal Quality Index [
17].
As above, $x$ and $y$ are discrete non-negative signals; $\mu_x$, $\sigma_{x}^2$, and $\sigma_{xy}$ are the mean value of $x$, the variance of $x$, and the covariance of $x$ and $y$, respectively. According to [
18] the luminance, contrast, and structure comparison measures were given as follows:
where $C_1$, $C_2$ and $C_3$ are small constants given by $C_1 = (K_1\cdot L)^2$ ; $C_2 = (K_2 \cdot L)^2$ and $C_3 = C_2/2$. Here $L$ is the dynamic range of the pixel values, and $K_1 \ll 1$ and $K_2 \ll 1$ are two scalar constants. The general form of the Structural SIMilarity (SSIM) index between signal x and y is defined as: 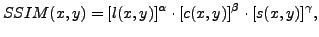 | (10) |
where $\alpha, \beta, \; \text{and} \; \gamma$ are parameters to define the relative importance of the three components [
18]. If
$\alpha= \beta= \gamma =1$, the resulting SSIM index is given by:
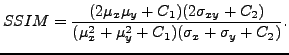 | (11) |
SSIM is maximal when two images are coinciding (i.e., SSIM is <=1 ). The universal image quality index proposed in [
17] corresponds to the case of
$C_1 = C_2 = 0$ , therefore is a special case of Eq. (
11).
A drawback of the basic SSIM index is its sensitivity to relative translations, scalings and rotations of images [18]. To handle such situations, a waveletdomain version of SSIM, called the complex wavelet SSIM (CW-SSIM) index was developed [25]. The CWSSIM index is also inspired by the fact that local phase contains more structural information than magnitude in natural images [26], while rigid translations of image structures leads to consistent phase shifts.
Despite its simplicity, the SSIM index performs remarkably well [18] across a wide variety of image and distortion types as has been shown in intensive human studies [27].
As it was said in [
18],
``we hope to inspire signal processing engineers to rethink whether the MSE is truly the criterion of choice in their own theories and applications, and whether it is time to look for alternatives.'' And I think that such articles provide a great deal of precious information for making decision to give away the MSE.
Useful links:A
very good and brief survey of images quality metrics, with links to MATLAB examples. Zhou Wang's page with huge amount of articles and MATLAB
source code for UQI and
SSIM. Another useful link for
HDR images quality metrics.
- 1
- Aleksandr Shnayderman, Alexander Gusev, and Ahmet M. Eskicioglu.
A multidimensional image quality measure using singular value decomposition.
In Image Quality and System Performance. Edited by Miyake, Yoichi; Rasmussen, D. Rene. Proceedings of the SPIE, Volume 5294, pp. 82-92, 2003. - 2
- A. M. Eskicioglu and P. S. Fisher.
A survey of image quality measures for gray scale image compression.
In Proceedings of 1993 Space and Earth Science Data Compression Workshop, pp. 49-61, Snowbird, UT, April 2, 1993. - 3
- Ligang Lu Zhou Wang, Alan C. Bovik.
Why is image quality assessment so difficult?
In In: Proceedings of the ICASSP'02, vol. 4, pp. IV-3313-IV-3316., 2002. - 4
- W. K. Pratt.
Digital Image Processing.
John Wiley and Sons, Inc., USA, 1978. - 5
- J.R. Fienup.
Invariant error metrics for image reconstruction.
Applied Optics, No 32, 36:8352-57, 1997. - 6
- J. L. Mannos and D. J. Sakrison.
The effects of a visual fidelity criterion on the encoding of images,.
IEEE Transactions on Information Theory, Vol. 20, No. 4:525-536, July 1974. - 7
- J. O. Limb.
Distortion criteria of the human viewer.
IEEE Transactions on Systems, Man, and Cybernetics, Vol. 9, No. 12:778-793, December 1979. - 8
- H. Marmolin.
Subjective mse measures.
IEEE Transactions on Systems, Man, and Cybernetics, Vol. 16, No. 3:486-489, May/June 1986. - 9
- J. A. Saghri, P. S. Cheatham, and A. Habibi.
Image quality measure based on a human visual system model.
Optical Engineering, Vol. 28, No. 7:813-818, July 1989. - 10
- B. N. Norman and H. B. Brian.
Objective image quality measure derived from digital image power spectra.
Optical Engineering, 31(4):813-825, 1992. - 11
- A.A. Webster, C. T. Jones, M. H. Pinson, S. D. Voran, and S. Wolf.
An objective video quality assessment system based on human perception.
In Proceedings of SPIE, Vol. 1913, 1993. - 12
- T. N. Pappas and R. J. Safranek.
in book ``Handbook of Image and Video Processing'' (A.Bovik, ed.), chapter Perceptual criteria for image quality evaluation.
Academic Press, May 2000. - 13
- B. Girod.
in book Digital Images and Human Vision (A. B. Watson, ed.), chapter What's wrong with mean-squared error, pages 207-220.
the MIT press, 1993. - 14
- S. Daly.
The visible difference predictor: An algorithm for the assessment of image fidelity.
In in Proceedings of SPIE, vol. 1616, pp. 2-15, 1992. - 15
- A. B. Watson, J. Hu, and J. F. III. McGowan.
Digital video quality metric based on human vision.
Journal of Electronic Imaging, vol. 10, no. 1:20-29, 2001. - 16
- J.-B. Martens and L. Meesters.
Image dissimilarity.
Signal Processing, vol. 70:155-176, Nov. 1998. - 17
- Z. Wang and A.C. Bovik.
A universal image quality index.
IEEE Signal Processing Letters, vol. 9, no. 3:81-84, Mar. 2002. - 18
- Z. Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli.
Image quality assessment: From error visibility to structural similarity.
IEEE Transactions on Image Processing, vol. 13, no. 4:600-612, Apr. 2004. - 19
- Zhou Wang and Alan C. Bovik.
Mean squared error: Love it or leave it?
IEEE Signal Processing Magazine, 98:98-117, January 2009. - 20
- D.M. Chandler and S.S. Hemami.
Vsnr: A wavelet-based visual signal-to-noise ratio for natural images.
IEEE Transactions on Image Processing, vol. 16, no. 9:2284-2298, Sept. 2007. - 21
- Wiener N.
The extrapolation, interpolation and smoothing of stationary time series.
New York: Wiley, page 163р, 1949. - 22
- J.R. Fienup.
Refined wiener-helstrom image reconstruction.
Annual Meeting of the Optical Society of America, Long Beach, CA, October 18, 2001. - 23
- James R. Fienup, Douglas K. Griffith, L. Harrington, A. M. Kowalczyk, Jason J. Miller, and James A. Mooney.
Comparison of reconstruction algorithms for images from sparse-aperture systems.
In Proc. SPIE, Image Reconstruction from Incomplete Data II, volume 4792, pages 1-8, 2002. - 24
- D. Kahaner, C. Moler, and S. Nash.
Numerical Methods and Software.
Prentice-Hall, Inc., 1989. - 25
- Z. Wang and E.P. Simoncelli.
Translation insensitive image similarity in complex wavelet domain.
In Proceedings of IEEE International Conference of Acoustics, Speech, and Signal Processing, pp. 573-576., Mar. 2005. - 26
- T.S. Huang, J.W. Burdett, and A.G. Deczky.
The importance of phase in image processing filters.
IEEE Transactions on Acoustic, Speech, and Signal Processing, vol. 23, no. 6:529-542, Dec. 1975. - 27
- H.R. Sheikh, M.F. Sabir, and A.C. Bovik.
A statistical evaluation of recent full reference image quality assessment algorithms.
IEEE Transactions on Image Processing, vol. 15, no. 11:3449-3451, Nov. 2006.

 That is enough for recalculation of the whole filtering sequence.
That is enough for recalculation of the whole filtering sequence.  In order to change the intensity scale of the image, just left-drag to set number of brightness or contrast magnification. It does not affect on the real image's values but just for viewing.
In order to change the intensity scale of the image, just left-drag to set number of brightness or contrast magnification. It does not affect on the real image's values but just for viewing. The reverse Fourier can be performed likewise using Toolkits - Math - Fourier - Reverse .
The reverse Fourier can be performed likewise using Toolkits - Math - Fourier - Reverse . As a result, we have a beautiful and informative histogram for the image.
As a result, we have a beautiful and informative histogram for the image. Or, using menu one can select the region of interest likewise: File - New - New Region.
Or, using menu one can select the region of interest likewise: File - New - New Region.
 This is much more easy and way faster than in Photoshop or Gimp: I have glued together 10x10 images each of which is 3000x2000 pixels on a notebook computer with only 512Mb RAM.
This is much more easy and way faster than in Photoshop or Gimp: I have glued together 10x10 images each of which is 3000x2000 pixels on a notebook computer with only 512Mb RAM.  Such function restores correct illumination on the image (to some extent, of course).
Such function restores correct illumination on the image (to some extent, of course).